User Interface Guide
- Making open source more inclusive
- 1. Introduction
- 2. User interface views
- 3. Installing the Migration Toolkit for Applications user interface
- 3.1. Persistent volume requirements
- 3.2. Installing the Migration Toolkit for Applications Operator and the user interface
- 3.3. Installing the Migration Toolkit for Applications Operator in a disconnected Red Hat OpenShift environment
- 3.4. Memory requirements for running MTA on Red Hat OpenShift Local
- 3.5. Red Hat Single Sign-On
- 4. Configuring the instance environment
- 5. Creating and configuring a Jira connection
- 6. Managing applications with MTA
- 7. Assessing and analyzing applications with MTA
- 7.1. The Assessment module features
- 7.2. MTA assessment questionnaires
- 7.3. Managing assessment questionnaires
- 7.4. Assessing an application
- 7.5. Reviewing an application
- 7.6. Reviewing an assessment report
- 7.7. Tagging an application
- 7.8. Working with archetypes
- 7.9. Analyzing an application
- 7.10. Creating custom migration targets
Making open source more inclusive
Red Hat is committed to replacing problematic language in our code, documentation, and web properties. We are beginning with these four terms: master, slave, blacklist, and whitelist. Because of the enormity of this endeavor, these changes will be implemented gradually over several upcoming releases. For more details, see our CTO Chris Wright’s message.
1. Introduction
1.1. About the User Interface Guide
This guide is for architects, engineers, consultants, and others who want to use the Migration Toolkit for Applications (MTA) user interface to accelerate large-scale application modernization efforts across hybrid cloud environments on Red Hat OpenShift. This solution provides insight throughout the adoption process, at both the portfolio and application levels: inventory, assess, analyze, and manage applications for faster migration to OpenShift via the user interface.
|
Note
|
The migration solution that was provided in the Migration Toolkit for Applications 5.x releases (migration and modernization of Java applications) is now available with Migration Toolkit for Runtimes 1.0. |
1.2. About the Migration Toolkit for Applications
What is the Migration Toolkit for Applications?
Migration Toolkit for Applications (MTA) accelerates large-scale application modernization efforts across hybrid cloud environments on Red Hat OpenShift. This solution provides insight throughout the adoption process, at both the portfolio and application levels: inventory, assess, analyze, and manage applications for faster migration to OpenShift via the user interface.
MTA uses an extensive default questionnaire as the basis for assessing your applications, or you can create your own custom questionnaire, enabling you to estimate the difficulty, time, and other resources needed to prepare an application for containerization. You can use the results of an assessment as the basis for discussions between stakeholders to determine which applications are good candidates for containerization, which require significant work first, and which are not suitable for containerization.
MTA analyzes applications by applying one or more rulesets to each application considered to determine which specific lines of that application must be modified before it can be modernized.
MTA examines application artifacts, including project source directories and application archives, and then produces an HTML report highlighting areas needing changes.
How does the Migration Toolkit for Applications simplify migration?
The Migration Toolkit for Applications looks for common resources and known trouble spots when migrating applications. It provides a high-level view of the technologies used by the application.
MTA generates a detailed report evaluating a migration or modernization path. This report can help you to estimate the effort required for large-scale projects and to reduce the work involved.
1.3. About the user interface
The user interface for the Migration Toolkit for Applications allows a team of users to assess and analyze applications for risks and suitability for migration to hybrid cloud environments on Red Hat OpenShift.
Use the user interface to assess and analyze your applications to get insights about potential pitfalls in the adoption process, at both the portfolio and application levels as you inventory, assess, analyze, and manage applications for faster migration to OpenShift.
2. User interface views
The Migration Toolkit for Applications (MTA) user interface has two views:
-
Administration view
-
Migration view
In Administration view, you configure the instance environment, working with credentials, repositories, HTTP and HTTPS proxy definitions, custom migration targets, and issue management.
In Migration view, you perform application assessments and analyses, review reports, and add applications for assessment and analysis.
3. Installing the Migration Toolkit for Applications user interface
You can install the Migration Toolkit for Applications (MTA) user interface on all Red Hat OpenShift cloud services and Red Hat OpenShift self-managed editions.
|
Important
|
To be able to create MTA instances, you must first install the MTA Operator. |
The MTA Operator is a structural layer that manages resources deployed on OpenShift, such as database, front end, and back end, to automatically create an MTA instance.
3.1. Persistent volume requirements
To successfully deploy, the MTA Operator requires 3 RWO persistent volumes (PVs) used by different components. If the rwx_supported configuration option is set to true, the MTA Operator requires an additional 2 RWX PVs that are used by Maven and the hub file storage. The PVs are described in the table below:
| Name | Default size | Access mode | Description |
|---|---|---|---|
|
10 GiB |
RWO |
Hub database |
|
100 GiB |
RWX |
Hub file storage; required if the |
|
1 GiB |
RWO |
Keycloak back end database |
|
1 GiB |
RWO |
Pathfinder back end database |
|
100 GiB |
RWX |
Maven m2 cache; required if the |
3.2. Installing the Migration Toolkit for Applications Operator and the user interface
You can install the Migration Toolkit for Applications (MTA) and the user interface on Red Hat OpenShift versions 4.13-4.15.
-
4 vCPUs, 8 GiB RAM, and 40 GiB persistent storage.
-
Any cloud services or self-hosted edition of Red Hat OpenShift on versions 4.13-4.15.
-
You must be logged in as a user with
cluster-adminpermissions.
For more information, see OpenShift Operator Life Cycles.
-
In the Red Hat OpenShift web console, click Operators → OperatorHub.
-
Use the Filter by keyword field to search for MTA.
-
Click the Migration Toolkit for Applications Operator and then click Install.
-
On the Install Operator page, click Install.
-
Click Operators → Installed Operators to verify that the MTA Operator appears in the
openshift-mtaproject with the statusSucceeded. -
Click the MTA Operator.
-
Under Provided APIs, locate Tackle, and click Create Instance.
The Create Tackle window opens in Form view.
-
Review the custom resource (CR) settings. The default choices should be acceptable, but make sure to check the system requirements for storage, memory, and cores.
-
To work directly with the YAML file, click YAML view and review the CR settings that are listed in the
specsection of the YAML file.The most commonly used CR settings are listed in this table:
Table 2. Tackle CR settings Name Default Description cache_data_volume_size100 GiBSize requested for the cache volume; ignored when
rwx_supported=falsecache_storage_classDefault storage class
Storage class used for the cache volume; ignored when
rwx_supported=falsefeature_auth_requiredTrueFlag to indicate whether keycloak authorization is required (single user/“noauth”)
feature_isolate_namespaceTrueFlag to indicate whether namespace isolation using network policies is enabled
hub_database_volume_size10 GiBSize requested for the Hub database volume
hub_bucket_volume_size100 GiBSize requested for the Hub bucket volume
hub_bucket_storage_classDefault storage class
Storage class used for the bucket volume
keycloak_database_data_volume_size1 GiBSize requested for the Keycloak database volume
pathfinder_database_data_volume_size1 GiBSize requested for the Pathfinder database volume
maven_data_volume_size100 GiBSize requested for the Maven m2 cache volume; deprecated in MTA 6.0.1
rwx_storage_classNA
Storage class requested for the Tackle RWX volumes; deprecated in MTA 6.0.1
rwx_supportedTrueFlag to indicate whether the cluster storage supports RWX mode
rwo_storage_classNA
Storage class requested for the Tackle RW0 volumes
rhsso_external_accessFalseFlag to indicate whether a dedicated route is created to access the MTA managed RHSSO instance
analyzer_container_limits_cpu1Maximum number of CPUs the pod is allowed to use
analyzer_container_limits_memory4GiBMaximum amount of memory the pod is allowed to use. You can increase this limit if the pod displays
OOMKillederrors.analyzer_container_requests_cpu1Minimum number of CPUs the pod needs to run
analyzer_container_requests_memory4GiBMinimum amount of memory the pod needs to run
Example YAML filekind: Tackle apiVersion: tackle.konveyor.io/v1alpha1 metadata: name: mta namespace: openshift-mta spec: hub_bucket_volume_size: "25Gi" maven_data_volume_size: "25Gi" rwx_supported: "false"
-
Edit the CR settings if needed, and then click Create.
-
In Administration view, click Workloads → Pods to verify that the MTA pods are running.
-
Access the user interface from your browser by using the route exposed by the
mta-uiapplication within OpenShift. -
Use the following credentials to log in:
-
User name: admin
-
Password: Passw0rd!
-
-
When prompted, create a new password.
3.3. Installing the Migration Toolkit for Applications Operator in a disconnected Red Hat OpenShift environment
You can install the MTA Operator in a disconnected environment by following the instructions in generic procedure.
In step 1 of the generic procedure, configure the image set for mirroring as follows:
kind: ImageSetConfiguration
apiVersion: mirror.openshift.io/v1alpha2
storageConfig:
registry:
imageURL: registry.to.mirror.to
skipTLS: false
mirror:
operators:
- catalog: registry.redhat.io/redhat/redhat-operator-index:v4.15
packages:
- name: mta-operator
channels:
- name: stable-v7.0
- name: rhsso-operator
channels:
- name: stable
helm: {}3.4. Memory requirements for running MTA on Red Hat OpenShift Local
When installed on Red Hat OpenShift Local, MTA requires a minimum amount of memory to complete its analysis. Adding memory makes the analysis process run faster. The table below describes the MTA performance with varying amounts of memory.
| Memory (GiB) | Description |
|---|---|
|
MTA cannot run the analysis due to insufficient memory |
|
MTA cannot run the analysis due to insufficient memory |
|
MTA works and the analysis is completed in approximately 3 minutes |
|
MTA works and the analysis is completed in less than 2 minutes |
|
MTA works quickly, and the analysis is completed in less than 1 minute |
The test results indicate that the minimum amount of memory for running MTA on OpenShift Local is 12 GiB.
|
Note
|
|
3.4.1. Eviction threshold
Each node has a certain amount of memory allocated to it. Some of that memory is reserved for system services. The rest of the memory is intended for running pods. If the pods use more than their allocated amount of memory, an out-of-memory event is triggered and the node is terminated with a OOMKilled error.
To prevent out-of-memory events and protect nodes, use the --eviction-hard setting. This setting specifies the threshold of memory availability below which the node evicts pods. The value of the setting can be absolute or a percentage.
-
Node capacity:
32 GiB -
--system-reservedsetting:3 GiB -
--eviction-hardsetting:100 MiB
The amount of memory available for running pods on this node is 28.9 GiB. This amount is calculated by subtracting the system-reserved and eviction-hard values from the overall capacity of the node. If the memory usage exceeds this amount, the node starts evicting pods.
3.5. Red Hat Single Sign-On
MTA delegates authentication and authorization to a Red Hat Single Sign-On (RHSSO) instance managed by the MTA operator. Aside from controlling the full lifecycle of the managed RHSSO instance, the MTA operator also manages the configuration of a dedicated realm that contains all the roles and permissions that MTA requires.
If an advanced configuration is required in the MTA managed RHSSO instance, such as adding
a provider for User Federation or integrating
identity providers, users can log into the RHSSO Admin
Console through the /auth/admin subpath in the mta-ui route. The admin credentials to access the MTA managed RHSSO instance can be retrieved from the credential-mta-rhsso secret available in the namespace in which the user interface was installed.
A dedicated route for the MTA managed RHSSO instance can be created by setting the rhsso_external_access parameter to True in the Tackle CR that manages the MTA instance.
For more information, see Red Hat Single Sign-On features and concepts.
3.5.1. Roles and Permissions
The following table contains the roles and permissions (scopes) that MTA seeds the managed RHSSO instance with:
tackle-admin |
Resource Name |
Verbs |
addons |
delete |
|
adoptionplans |
post |
|
applications |
delete |
|
applications.facts |
delete |
|
applications.tags |
delete |
|
applications.bucket |
delete |
|
assessments |
delete |
|
businessservices |
delete |
|
dependencies |
delete |
|
identities |
delete |
|
imports |
delete |
|
jobfunctions |
delete |
|
proxies |
delete |
|
reviews |
delete |
|
settings |
delete |
|
stakeholdergroups |
delete |
|
stakeholders |
delete |
|
tags |
delete |
|
tagtypes |
delete |
|
tasks |
delete |
|
tasks.bucket |
delete |
|
tickets |
delete |
|
trackers |
delete |
|
cache |
delete |
|
files |
delete |
|
rulebundles |
delete |
|
tackle-architect |
Resource Name |
Verbs |
addons |
delete |
|
applications.bucket |
delete |
|
adoptionplans |
post |
|
applications |
delete |
|
applications.facts |
delete |
|
applications.tags |
delete |
|
assessments |
delete |
|
businessservices |
delete |
|
dependencies |
delete |
|
identities |
get |
|
imports |
delete |
|
jobfunctions |
delete |
|
proxies |
get |
|
reviews |
delete |
|
settings |
get |
|
stakeholdergroups |
delete |
|
stakeholders |
delete |
|
tags |
delete |
|
tagtypes |
delete |
|
tasks |
delete |
|
tasks.bucket |
delete |
|
trackers |
get |
|
tickets |
delete |
|
cache |
get |
|
files |
delete |
|
rulebundles |
delete |
|
tackle-migrator |
Resource Name |
Verbs |
addons |
get |
|
adoptionplans |
post |
|
applications |
get |
|
applications.facts |
get |
|
applications.tags |
get |
|
applications.bucket |
get |
|
assessments |
get |
|
businessservices |
get |
|
dependencies |
delete |
|
identities |
get |
|
imports |
get |
|
jobfunctions |
get |
|
proxies |
get |
|
reviews |
get |
|
settings |
get |
|
stakeholdergroups |
get |
|
stakeholders |
get |
|
tags |
get |
|
tagtypes |
get |
|
tasks |
delete |
|
tasks.bucket |
delete |
|
tackers |
get |
|
tickets |
get |
|
cache |
get |
|
files |
get |
|
rulebundles |
get |
4. Configuring the instance environment
You can configure the following in Administration view:
-
General
-
Credentials
-
Repositories
-
HTTP and HTTPS proxy settings
-
Custom migration targets
-
Issue management
4.1. General
You can enable or disable the following options:
-
Reviewing applications without running an assessment first
-
Downloading HTML reports
-
Downloading CSV reports
4.2. Configuring credentials
You can configure the following types of credentials in Administration view:
-
Source control
-
Maven
-
Proxy
4.2.1. Configuring source control credentials
You can configure source control credentials in the Credentials view of the Migration Toolkit for Applications (MTA) user interface.
-
In Administration view, click Credentials.
-
Click Create new.
-
Enter the following information:
-
Name
-
Description (Optional)
-
-
In the Type list, select Source Control.
-
In the User credentials list, select Credential Type and enter the requested information:
-
Username/Password
-
Username
-
Password (hidden)
-
-
SCM Private Key/Passphrase
-
SCM Private Key
-
Private Key Passphrase (hidden)
NoteType-specific credential information such as keys and passphrases is either hidden or shown as [Encrypted].
-
-
-
Click Create.
MTA validates the input and creates a new credential. SCM keys must be parsed and checked for validity. If the validation fails, the following error message is displayed:
“not a valid key/XML file”.
4.2.2. Configuring Maven credentials
You can configure new Maven credentials in the Credentials view of the Migration Toolkit for Applications (MTA) user interface.
-
In Administration view, click Credentials.
-
Click Create new.
-
Enter the following information:
-
Name
-
Description (Optional)
-
-
In the Type list, select Maven Settings File.
-
Upload the settings file or paste its contents.
-
Click Create.
MTA validates the input and creates a new credential. The Maven
settings.xmlfile must be parsed and checked for validity. If the validation fails, the following error message is displayed:“not a valid key/XML file”.
4.2.3. Configuring proxy credentials
You can configure proxy credentials in the Credentials view of the Migration Toolkit for Applications (MTA) user interface.
-
In Administration view, click Credentials.
-
Click Create new.
-
Enter the following information:
-
Name
-
Description (Optional)
-
-
In the Type list, select Proxy.
-
Enter the following information.
-
Username
-
Password
NoteType-specific credential information such as keys and passphrases is either hidden or shown as [Encrypted].
-
-
Click Create.
MTA validates the input and creates a new credential.
4.3. Configuring repositories
You can configure the following types of repositories in Administration view:
-
Git
-
Subversion
-
Maven
4.3.1. Configuring Git repositories
You can configure Git repositories in the Repositories view of the Migration Toolkit for Applications (MTA) user interface.
-
In Administration view, click Repositories and then click Git.
-
Toggle the Consume insecure Git repositories switch to the right.
4.3.2. Configuring subversion repositories
You can configure subversion repositories in the Repositories view of the Migration Toolkit for Applications (MTA) user interface.
-
In Administration view, click Repositories and then click Subversion.
-
Toggle the Consume insecure Subversion repositories switch to the right.
4.3.3. Configuring a Maven repository and reducing its size
You can use the MTA user interface to both configure a Maven repository and to reduce its size.
Configuring a Maven repository
You can configure a Maven repository in the Repositories view of the Migration Toolkit for Applications (MTA) user interface.
|
Note
|
If the |
-
In Administration view, click Repositories and then click Maven.
-
Toggle the Consume insecure artifact repositories switch to the right.
Reducing the size of a Maven repository
You can reduce the size of a Maven repository in the Repositories view of the Migration Toolkit for Applications (MTA) user interface.
|
Note
|
If the |
-
In Administration view, click Repositories and then click Maven.
-
Click the Clear repository link.
NoteDepending on the size of the repository, the size change may not be evident despite the function working properly.
4.4. Configuring HTTP and HTTPS proxy settings
You can configure HTTP and HTTPS proxy settings with this management module.
-
In the Administration view, click Proxy.
-
Toggle HTTP proxy or HTTPS proxy to enable the proxy connection.
-
Enter the following information:
-
Proxy host
-
Proxy port
-
-
Optional: Toggle HTTP proxy credentials or HTTPS proxy credentials to enable authentication.
-
Click Insert.
4.5. Seeding an instance
If you are a project architect, you can configure the instance’s key parameters in the Controls window, before migration. The parameters can be added and edited as needed. The following parameters define applications, individuals, teams, verticals or areas within an organization affected or participating in the migration:
-
Stakeholders
-
Stakeholder groups
-
Job functions
-
Business services
-
Tag categories
-
Tags
You can create and configure an instance in any order. However, the suggested order below is the most efficient for creating stakeholders and tags.
Stakeholders:
-
Create Stakeholder groups
-
Create Job functions
-
Create Stakeholders
Tags:
-
Create Tag categories
-
Create Tags
Stakeholders and defined by:
-
Email
-
Name
-
Job function
-
Stakeholder groups
4.5.1. Creating a new stakeholder group
There are no default stakeholder groups defined. You can create a new stakeholder group by following the procedure below.
-
In Migration view, click Controls.
-
Click Stakeholder groups.
-
Click Create new.
-
Enter the following information:
-
Name
-
Description
-
Member(s)
-
-
Click Create.
4.5.2. Creating a new job function
Migration Toolkit for Applications (MTA) uses the job function attribute to classify stakeholders and provides a list of default values that can be expanded.
You can create a new job function, which is not in the default list, by following the procedure below.
-
In Migration view, click Controls.
-
Click Job functions.
-
Click Create new.
-
Enter a job function title in the Name text box.
-
Click Create.
4.5.3. Creating a new stakeholder
You can create a new migration project stakeholder by following the procedure below.
-
In Migration view, click Controls.
-
Click Stakeholders.
-
Click Create new.
-
Enter the following information:
-
Email
-
Name
-
Job function - custom functions can be created
-
Stakeholder group
-
-
Click Create.
4.5.4. Creating a new business service
Migration Toolkit for Applications (MTA) uses the business service attribute to specify the departments within the organization that use the application and that are affected by the migration.
You can create a new business service by following the procedure below.
-
In Migration view, click Controls.
-
Click Business services.
-
Click Create new.
-
Enter the following information:
-
Name
-
Description
-
Owner
-
-
Click Create.
4.5.5. Creating new tag categories
Migration Toolkit for Applications (MTA) uses tags in multiple categories and provides a list of default values. You can create a new tag category by following the procedure below.
-
In Migration view, click Controls.
-
Click Tags.
-
Click Create tag category.
-
Enter the following information:
-
Name
-
Rank - the order in which the tags appear on the applications
-
Color
-
-
Click Create.
Creating new tags
You can create a new tag, which is not in the default list, by following the procedure below.
-
In Migration view, click Controls.
-
Click Tags.
-
Click Create tag.
-
Enter the following information:
-
Name
-
Tag category
-
-
Click Create.
5. Creating and configuring a Jira connection
You can track application migrations by creating a Jira issue for each migration from within the MTA user interface. To be able to create Jira issues, you first need to do the following:
-
Create an MTA credential to authenticate to the API of the Jira instance that you create in the next step.
-
Create a Jira instance in MTA and establish a connection to that instance.
5.1. Configuring Jira credentials
To define a Jira instance in MTA and establish a connection to that instance, you must first create an MTA credential to authenticate to the Jira instance’s API.
Two types of credentials are available:
-
Basic auth - for Jira Cloud and a private Jira server or data center
-
Bearer Token - for a private Jira server or data center
To create an MTA credential, follow the procedure below.
-
In Administration view, click Credentials.
The Credentials page opens.
-
Click Create new.
-
Enter the following information:
-
Name
-
Description (optional)
-
-
In the Type list, select Basic Auth (Jira) or Bearer Token (Jira):
-
If you selected Basic Auth (Jira), proceed as follows:
-
In the Email field, enter your email.
-
In the Token field, depending on the specific Jira configuration, enter either your token generated on the Jira site or your Jira login password.
NoteTo obtain a Jira token, you need to log in to the Jira site.
-
Click Save.
The new credential appears on the Credentials page.
-
-
If you selected Bearer Token (Jira), proceed as follows:
-
In the Token field, enter your token generated on the Jira site.
-
Click Save.
The new credential appears on the Credentials page.
-
-
You can edit a credential by clicking Edit.
To delete a credential, click Delete.
|
Note
|
You cannot delete a credential that has already been assigned to a Jira connection instance. |
5.2. Creating and configuring a Jira connection
To create a Jira instance in MTA and establish a connection to that instance, follow the procedure below.
-
In Administration view, under Issue Management, click Jira.
The Jira configuration page opens.
-
Click Create new.
The New instance window opens.
-
Enter the following information:
-
Name of the instance
-
URL of the web interface of your Jira account
-
Instance type - select either Jira Cloud or Jira Server/Data center from the list
-
Credentials - select from the list
NoteIf the selected instance type is Jira Cloud, only Basic Auth credentials are displayed in the list.
If the selected instance type is Jira Server/Data center, both Basic Auth and Token Bearer credentials are displayed. Choose the type that is appropriate for the particular configuration of your Jira server or data center.
-
-
By default, a connection cannot be established with a server with an invalid certificate. To override this restriction, toggle the Enable insecure communication switch.
-
Click Create.
The new connection instance appears on the Jira configuration page.
Once the connection has been established and authorized, the status in the Connection column becomes Connected.
If the Connection status becomes
Not connected, click the status to see the reason for the error.
The Jira configuration table has filtering by Name and URL and sorting by Instance name and URL.
|
Note
|
A Jira connection that was used for creating issues for a migration wave cannot be removed as long as the issues exist in Jira, even after the migration wave is deleted. |
6. Managing applications with MTA
You can use the Migration Toolkit for Applications (MTA) user interface to perform the following tasks:
-
Add applications.
-
Assign application credentials.
-
Import a list of applications.
-
Download a CSV template for importing application lists.
-
Create application migration waves.
-
Create Jira issues for migration waves.
MTA user interface applications have the following attributes:
-
Name (free text)
-
Description (optional, free text)
-
Business service (optional, chosen from a list)
-
Tags (optional, chosen from a list)
-
Owner (optional, chosen from a list)
-
Contributors (optional, chosen from a list)
-
Source code (a path entered by the user)
-
Binary (a path entered by the user)
6.1. Adding a new application
You can add a new application to the Application Inventory for subsequent assessment and analysis.
|
Tip
|
Before creating an application, set up business services, check tags and tag categories, and create additions as needed. |
-
You are logged in to an MTA server.
-
In the Migration view, click Application Inventory.
-
Click Create new.
-
Under Basic information, enter the following fields:
-
Name: A unique name for the new application.
-
Description: A short description of the application (optional).
-
Business service: A purpose of the application (optional).
-
Manual tags: Software tags that characterize the application (optional, one or more).
-
Owner: A registered software owner from the drop-down list (optional).
-
Contributors: Contributors from the drop-down list (optional, one or more).
-
Comments: Relevant comments on the application (optional).
-
-
Click Source Code and enter the following fields:
-
Repository type: Git or Subversion.
-
Source repository: A URL of the repository where the software code is saved.
-
Branch: An application code branch in the repository (optional).
-
Root path: A root path inside the repository for the target application (optional).
NoteIf you enter any value in either the Branch or Root path fields, the Source repository field becomes mandatory. -
-
Optional: Click Binary and enter the following fields:
-
Group: The Maven group for the application artifact.
-
Artifact: The Maven artifact for the application.
-
Version: A software version of the application.
-
Packaging: The packaging for the application artifact, for example,
JAR,WAR, orEAR.
NoteIf you enter any value in any of the Binary section fields, all fields automatically become mandatory. -
-
Click Create. The new application appears in the list of defined applications.
6.2. Editing an application
You can edit an existing application in the Application Inventory and re-run an assessment or analysis for this application.
-
You are logged in to an MTA server.
-
In the Migration view, click Application Inventory.
-
Select the Migration working mode.
-
Click Application Inventory in the left menu bar. A list of available applications appears in the main pane.
-
Click Edit (
 ) to open the application settings.
) to open the application settings. -
Review the application settings. For a list of application settings, see Adding an application.
-
If you changed any application settings, click Save.
6.3. Assigning credentials to an application
You can assign credentials to one or more applications.
-
In the Migration view, click Application inventory.
-
Click the Options menu (
 ) to the right of Analyze and select Manage credentials.
) to the right of Analyze and select Manage credentials. -
Select one credential from the Source credentials list and from the Maven settings list.
-
Click Save.
6.4. Importing a list of applications
You can import a .csv file that contains a list of applications and their attributes to the Migration Toolkit for Applications (MTA) user interface.
|
Note
|
Importing a list of applications does not overwrite any of the existing applications. |
-
Review the import file to ensure it contains all the required information in the required format.
-
In the Migration view, click Application Inventory.
-
Click the Options menu (
). -
Click Import.
-
Select the desired file and click Open.
-
Optional: Select Enable automatic creation of missing entities. This option is selected by default.
-
Verify that the import has completed and check the number of accepted or rejected rows.
-
Review the imported applications by clicking the arrow to the left of the checkbox.
ImportantAccepted rows might not match the number of applications in the Application inventory list because some rows are dependencies. To verify, check the Record Type column of the CSV file for applications defined as 1and dependencies defined as2.
6.5. Downloading a CSV template
You can download a CSV template for importing application lists by using the Migration Toolkit for Applications (MTA) user interface.
-
In the Migration view, click Application inventory.
-
Click the Options menu (
) to the right of Review. -
Click Manage imports to open the Application imports page.
-
Click the Options menu (
) to the right of Import. -
Click Download CSV template.
6.6. Creating a migration wave
A migration wave is a group applications that you can migrate on a given schedule. You can track each migration by exporting a list of the wave’s applications to the Jira issue management system. This automatically creates a separate Jira issue for each application of the migration wave.
-
In the Migration view, click Migration waves.
-
Click Create new. The New migration wave window opens.
-
Enter the following information:
-
Name (optional). If the name is not given, you can use the start and end dates to identify migration waves.
-
Potential start date. This date must be later than the current date.
-
Potential end date. This date must be later than the start date.
-
Stakeholders (optional)
-
Stakeholder groups (optional)
-
-
Click Create. The new migration wave appears in the list of existing migration waves.
-
To assign applications to the migration wave, click the Options menu (
) to the right of the migration wave and select Manage applications.The Manage applications window opens that displays the list of applications that are not assigned to any other migration wave.
-
Select the checkboxes of the applications that you want to assign to the migration wave.
-
Click Save.
NoteThe owner and the contributors of each application associated with the migration wave are automatically added to the migration wave’s list of stakeholders. -
Optional: To update a migration wave, select Update from the migration wave’s Options menu (
). The Update migration wave window opens.
6.7. Creating Jira issues for a migration wave
You can use a migration wave to create Jira issues automatically for each application assigned to the migration wave. A separate Jira issue is created for each application associated with the migration wave. The following fields of each issue are filled in automatically:
-
Title:
Migrate <application name> -
Reporter: Username of the token owner.
-
Description:
Created by Konveyor
|
Note
|
You cannot delete an application if it is linked to a Jira ticket or is associated with a migration wave. To unlink the application from the Jira ticket, click the Unlink from Jira icon in the details view of the application or in the details view of a migration wave.
|
-
You configured Jira connection. For more information, see Creating and configuring a Jira connection.
-
In the Migration view, click Migration waves.
-
Click the Options menu (
) to the right of the migration wave for which you want to create Jira issues and select Export to Issue Manager. The Export to Issue Manager window opens. -
Select the Jira Cloud or Jira Server/Datacenter instance type.
-
Select the instance, project, and issue type from the lists.
-
Click Export. The status of the migration wave on the Migration waves page changes to
Issues Created. -
Optional: To see the status of each individual application of a migration wave, click the Status column.
-
Optional: To see if any particular application is associated with a migration wave, open the application’s Details tab on the Application inventory page.
7. Assessing and analyzing applications with MTA
You can use the Migration Toolkit for Applications (MTA) user interface to assess and analyze applications:
-
When assessing applications, MTA estimates the risks and costs involved in preparing applications for containerization, including time, personnel, and other factors. You can use the results of an assessment for discussions between stakeholders to determine whether applications are suitable for containerization.
-
When analyzing applications, MTA uses rules to determine which specific lines in an application must be modified before the application can be migrated or modernized.
7.1. The Assessment module features
The Migration Toolkit for Applications (MTA) Assessment module offers the following features for assessing and analyzing applications:
- Assessment hub
-
The Assessment hub integrates with the Application inventory.
- Enhanced assessment questionnaire capabilities
-
In MTA 7.0, you can import and export assessment questionnaires. You can also design custom questionnaires with a downloadable template by using the YAML syntax, which includes the following features:
-
Conditional questions: You can include or exclude questions based on the application or archetype if a certain tag is present on this application or archetype.
-
Application auto-tagging based on answers: You can define tags to be applied to applications or archetypes if a certain answer was provided.
-
Automated answers from tags in applications or archetypes.
For more information, see The custom assessment questionnaire.
-
|
Note
|
You can customize and save the default questionnaire. For more information, see The default assessment questionnaire. |
- Multiple assessment questionnaires
-
The Assessment module supports multiple questionnaires, relevant to one or more applications.
- Archetypes
-
You can group applications with similar characteristics into archetypes. This allows you to assess multiple applications at once. Each archetype has a shared taxonomy of tags, stakeholders, and stakeholder groups. All applications inherit assessment and review from their assigned archetypes.
For more information, see Working with archetypes.
7.2. MTA assessment questionnaires
The Migration Toolkit for Applications (MTA) uses an assessment questionnaire, either default or custom, to assess the risks involved in containerizing an application.
The assessment report provides information about applications and risks associated with migration. The report also generates an adoption plan informed by the prioritization, business criticality, and dependencies of the applications submitted for assessment.
7.2.1. The default assessment questionnaire
Legacy Pathfinder is the default Migration Toolkit for Applications (MTA) questionnaire. Pathfinder is a questionnaire-based tool that you can use to evaluate the suitability of applications for modernization in containers on an enterprise Kubernetes platform.
Through interaction with the default questionnaire and the review process, the system is enriched with application knowledge exposed through the collection of assessment reports.
You can export the default questionnaire to a YAML file:
name: Legacy Pathfinder
description: ''
sections:
- order: 1
name: Application details
questions:
- order: 1
text: >-
Does the application development team understand and actively develop
the application?
explanation: >-
How much knowledge does the team have about the application's
development or usage?
answers:
- order: 2
text: >-
Maintenance mode, no SME knowledge or adequate documentation
available
risk: red
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
Little knowledge, no development (example: third-party or
commercial off-the-shelf application)
risk: red
rationale: ''
mitigation: ''
- order: 3
text: Maintenance mode, SME knowledge is available
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Actively developed, SME knowledge is available
risk: green
rationale: ''
mitigation: ''
- order: 5
text: greenfield application
risk: green
rationale: ''
mitigation: ''
- order: 2
text: How is the application supported in production?
explanation: >-
Does the team have sufficient knowledge to support the application in
production?
answers:
- order: 3
text: >-
Multiple teams provide support using an established escalation
model
risk: yellow
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
External support provider with a ticket-driven escalation process;
no inhouse support resources
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Separate internal support team, separate from the development
team, with little interaction between the teams
risk: red
rationale: ''
mitigation: ''
- order: 4
text: >-
SRE (Site Reliability Engineering) approach with a knowledgeable
and experienced operations team
risk: green
rationale: ''
mitigation: ''
- order: 5
text: >-
DevOps approach with the same team building the application and
supporting it in production
risk: green
rationale: ''
mitigation: ''
- order: 3
text: >-
How much time passes from when code is committed until the application
is deployed to production?
explanation: What is the development latency?
answers:
- order: 3
text: 2-6 months
risk: yellow
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Not tracked
risk: red
rationale: ''
mitigation: ''
- order: 2
text: More than 6 months
risk: red
rationale: ''
mitigation: ''
- order: 4
text: 8-30 days
risk: green
rationale: ''
mitigation: ''
- order: 5
text: 1-7 days
risk: green
rationale: ''
mitigation: ''
- order: 6
text: Less than 1 day
risk: green
rationale: ''
mitigation: ''
- order: 4
text: How often is the application deployed to production?
explanation: Deployment frequency
answers:
- order: 3
text: Between once a month and once every 6 months
risk: yellow
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Not tracked
risk: red
rationale: ''
mitigation: ''
- order: 2
text: Less than once every 6 months
risk: red
rationale: ''
mitigation: ''
- order: 4
text: Weekly
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Daily
risk: green
rationale: ''
mitigation: ''
- order: 6
text: Several times a day
risk: green
rationale: ''
mitigation: ''
- order: 5
text: >-
What is the application's mean time to recover (MTTR) from failure in
a production environment?
explanation: Average time for the application to recover from failure
answers:
- order: 5
text: Less than 1 hour
risk: green
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Not tracked
risk: red
rationale: ''
mitigation: ''
- order: 3
text: 1-7 days
risk: yellow
rationale: ''
mitigation: ''
- order: 2
text: 1 month or more
risk: red
rationale: ''
mitigation: ''
- order: 4
text: 1-24 hours
risk: green
rationale: ''
mitigation: ''
- order: 6
text: Does the application have legal and/or licensing requirements?
explanation: >-
Legal and licensing requirements must be assessed to determine their
possible impact (cost, fault reporting) on the container platform
hosting the application. Examples of legal requirements: isolated
clusters, certifications, compliance with the Payment Card Industry
Data Security Standard or the Health Insurance Portability and
Accountability Act. Examples of licensing requirements: per server,
per CPU.
answers:
- order: 1
text: Multiple legal and licensing requirements
risk: red
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 2
text: 'Licensing requirements (examples: per server, per CPU)'
risk: red
rationale: ''
mitigation: ''
- order: 3
text: >-
Legal requirements (examples: cluster isolation, hardware, PCI or
HIPAA compliance)
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: None
risk: green
rationale: ''
mitigation: ''
- order: 7
text: Which model best describes the application architecture?
explanation: Describe the application architecture in simple terms.
answers:
- order: 3
text: >-
Complex monolith, strict runtime dependency startup order,
non-resilient architecture
risk: yellow
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 5
text: Independently deployable components
risk: green
rationale: ''
mitigation: ''
- order: 1
text: >-
Massive monolith (high memory and CPU usage), singleton
deployment, vertical scale only
risk: yellow
rationale: ''
mitigation: ''
- order: 2
text: >-
Massive monolith (high memory and CPU usage), non-singleton
deployment, complex to scale horizontally
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: 'Resilient monolith (examples: retries, circuit breakers)'
risk: green
rationale: ''
mitigation: ''
- order: 2
name: Application dependencies
questions:
- order: 1
text: Does the application require specific hardware?
explanation: >-
OpenShift Container Platform runs only on x86, IBM Power, or IBM Z
systems
answers:
- order: 3
text: 'Requires specific computer hardware (examples: GPUs, RAM, HDDs)'
risk: yellow
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Requires CPU that is not supported by red Hat
risk: red
rationale: ''
mitigation: ''
- order: 2
text: 'Requires custom or legacy hardware (example: USB device)'
risk: red
rationale: ''
mitigation: ''
- order: 4
text: Requires CPU that is supported by red Hat
risk: green
rationale: ''
mitigation: ''
- order: 2
text: What operating system does the application require?
explanation: >-
Only Linux and certain Microsoft Windows versions are supported in
containers. Check the latest versions and requirements.
answers:
- order: 4
text: Microsoft Windows
risk: yellow
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
Operating system that is not compatible with OpenShift Container
Platform (examples: OS X, AIX, Unix, Solaris)
risk: red
rationale: ''
mitigation: ''
- order: 2
text: Linux with custom kernel drivers or a specific kernel version
risk: red
rationale: ''
mitigation: ''
- order: 3
text: 'Linux with custom capabilities (examples: seccomp, root access)'
risk: yellow
rationale: ''
mitigation: ''
- order: 5
text: Standard Linux distribution
risk: green
rationale: ''
mitigation: ''
- order: 3
text: >-
Does the vendor provide support for a third-party component running in
a container?
explanation: Will the vendor support a component if you run it in a container?
answers:
- order: 2
text: No vendor support for containers
risk: red
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Not recommended to run the component in a container
risk: red
rationale: ''
mitigation: ''
- order: 3
text: >-
Vendor supports containers but with limitations (examples:
functionality is restricted, component has not been tested)
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: >-
Vendor supports their application running in containers but you
must build your own images
risk: yellow
rationale: ''
mitigation: ''
- order: 5
text: Vendor fully supports containers, provides certified images
risk: green
rationale: ''
mitigation: ''
- order: 6
text: No third-party components required
risk: green
rationale: ''
mitigation: ''
- order: 4
text: Incoming/northbound dependencies
explanation: Systems or applications that call the application
answers:
- order: 3
text: >-
Many dependencies exist, can be changed because the systems are
internally managed
risk: green
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 4
text: Internal dependencies only
risk: green
rationale: ''
mitigation: ''
- order: 1
text: >-
Dependencies are difficult or expensive to change because they are
legacy or third-party
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Many dependencies exist, can be changed but the process is
expensive and time-consuming
risk: yellow
rationale: ''
mitigation: ''
- order: 5
text: No incoming/northbound dependencies
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Outgoing/southbound dependencies
explanation: Systems or applications that the application calls
answers:
- order: 3
text: Application not ready until dependencies are verified available
risk: yellow
rationale: ''
mitigation: ''
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
Dependency availability only verified when application is
processing traffic
risk: red
rationale: ''
mitigation: ''
- order: 2
text: Dependencies require a complex and strict startup order
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Limited processing available if dependencies are unavailable
risk: green
rationale: ''
mitigation: ''
- order: 5
text: No outgoing/southbound dependencies
risk: green
rationale: ''
mitigation: ''
- order: 3
name: Application architecture
questions:
- order: 1
text: >-
How resilient is the application? How well does it recover from
outages and restarts?
explanation: >-
If the application or one of its dependencies fails, how does the
application recover from failure? Is manual intervention required?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
Application cannot be restarted cleanly after failure, requires
manual intervention
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Application fails when a soutbound dependency is unavailable and
does not recover automatically
risk: red
rationale: ''
mitigation: ''
- order: 3
text: >-
Application functionality is limited when a dependency is
unavailable but recovers when the dependency is available
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: >-
Application employs resilient architecture patterns (examples:
circuit breakers, retry mechanisms)
risk: green
rationale: ''
mitigation: ''
- order: 5
text: >-
Application containers are randomly terminated to test resiliency;
chaos engineering principles are followed
risk: green
rationale: ''
mitigation: ''
- order: 2
text: How does the external world communicate with the application?
explanation: >-
What protocols do external clients use to communicate with the
application?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: 'Non-TCP/IP protocols (examples: serial, IPX, AppleTalk)'
risk: red
rationale: ''
mitigation: ''
- order: 2
text: TCP/IP, with host name or IP address encapsulated in the payload
risk: red
rationale: ''
mitigation: ''
- order: 3
text: 'TCP/UDP without host addressing (example: SSH)'
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: TCP/UDP encapsulated, using TLS with SNI header
risk: green
rationale: ''
mitigation: ''
- order: 5
text: HTTP/HTTPS
risk: green
rationale: ''
mitigation: ''
- order: 3
text: How does the application manage its internal state?
explanation: >-
If the application must manage or retain an internal state, how is
this done?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 3
text: State maintained in non-shared, non-ephemeral storage
risk: yellow
rationale: ''
mitigation: ''
- order: 1
text: Application components use shared memory within a pod
risk: yellow
rationale: ''
mitigation: ''
- order: 2
text: >-
State is managed externally by another product (examples:
Zookeeper or red Hat Data Grid)
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Disk shared between application instances
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Stateless or ephemeral container storage
risk: green
rationale: ''
mitigation: ''
- order: 4
text: How does the application handle service discovery?
explanation: How does the application discover services?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
Uses technologies that are not compatible with Kubernetes
(examples: hardcoded IP addresses, custom cluster manager)
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Requires an application or cluster restart to discover new service
instances
risk: red
rationale: ''
mitigation: ''
- order: 3
text: >-
Uses technologies that are compatible with Kubernetes but require
specific libraries or services (examples: HashiCorp Consul,
Netflix Eureka)
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Uses Kubernetes DNS name resolution
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Does not require service discovery
risk: green
rationale: ''
mitigation: ''
- order: 5
text: How is the application clustering managed?
explanation: >-
Does the application require clusters? If so, how is clustering
managed?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: 'Manually configured clustering (example: static clusters)'
risk: red
rationale: ''
mitigation: ''
- order: 2
text: Managed by an external off-PaaS cluster manager
risk: red
rationale: ''
mitigation: ''
- order: 3
text: >-
Managed by an application runtime that is compatible with
Kubernetes
risk: green
rationale: ''
mitigation: ''
- order: 4
text: No cluster management required
risk: green
rationale: ''
mitigation: ''
- order: 4
name: Application observability
questions:
- order: 1
text: How does the application use logging and how are the logs accessed?
explanation: How the application logs are accessed
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Logs are unavailable or are internal with no way to export them
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Logs are in a custom binary format, exposed with non-standard
protocols
risk: red
rationale: ''
mitigation: ''
- order: 3
text: Logs are exposed using syslog
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Logs are written to a file system, sometimes as multiple files
risk: yellow
rationale: ''
mitigation: ''
- order: 5
text: 'Logs are forwarded to an external logging system (example: Splunk)'
risk: green
rationale: ''
mitigation: ''
- order: 6
text: 'Logs are configurable (example: can be sent to stdout)'
risk: green
rationale: ''
mitigation: ''
- order: 2
text: Does the application provide metrics?
explanation: >-
Are application metrics available, if necessary (example: OpenShift
Container Platform collects CPU and memory metrics)?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: No metrics available
risk: yellow
rationale: ''
mitigation: ''
- order: 2
text: Metrics collected but not exposed externally
risk: yellow
rationale: ''
mitigation: ''
- order: 3
text: 'Metrics exposed using binary protocols (examples: SNMP, JMX)'
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: >-
Metrics exposed using a third-party solution (examples: Dynatrace,
AppDynamics)
risk: green
rationale: ''
mitigation: ''
- order: 5
text: >-
Metrics collected and exposed with built-in Prometheus endpoint
support
risk: green
rationale: ''
mitigation: ''
- order: 3
text: >-
How easy is it to determine the application's health and readiness to
handle traffic?
explanation: >-
How do we determine an application's health (liveness) and readiness
to handle traffic?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: No health or readiness query functionality available
risk: red
rationale: ''
mitigation: ''
- order: 3
text: Basic application health requires semi-complex scripting
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Dedicated, independent liveness and readiness endpoints
risk: green
rationale: ''
mitigation: ''
- order: 2
text: Monitored and managed by a custom watchdog process
risk: red
rationale: ''
mitigation: ''
- order: 5
text: Health is verified by probes running synthetic transactions
risk: green
rationale: ''
mitigation: ''
- order: 4
text: What best describes the application's runtime characteristics?
explanation: >-
How would the profile of an application appear during runtime
(examples: graphs showing CPU and memory usage, traffic patterns,
latency)? What are the implications for a serverless application?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
Deterministic and predictable real-time execution or control
requirements
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Sensitive to latency (examples: voice applications, high frequency
trading applications)
risk: yellow
rationale: ''
mitigation: ''
- order: 3
text: Constant traffic with a broad range of CPU and memory usage
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Intermittent traffic with predictable CPU and memory usage
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Constant traffic with predictable CPU and memory usage
risk: green
rationale: ''
mitigation: ''
- order: 5
text: How long does it take the application to be ready to handle traffic?
explanation: How long the application takes to boot
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: More than 5 minutes
risk: red
rationale: ''
mitigation: ''
- order: 2
text: 2-5 minutes
risk: yellow
rationale: ''
mitigation: ''
- order: 3
text: 1-2 minutes
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: 10-60 seconds
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Less than 10 seconds
risk: green
rationale: ''
mitigation: ''
- order: 5
name: Application cross-cutting concerns
questions:
- order: 1
text: How is the application tested?
explanation: >-
Is the application is tested? Is it easy to test (example: automated
testing)? Is it tested in production?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: No testing or minimal manual testing only
risk: red
rationale: ''
mitigation: ''
- order: 2
text: Minimal automated testing, focused on the user interface
risk: yellow
rationale: ''
mitigation: ''
- order: 3
text: >-
Some automated unit and regression testing, basic CI/CD pipeline
testing; modern test practices are not followed
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: >-
Highly repeatable automated testing (examples: unit, integration,
smoke tests) before deploying to production; modern test practices
are followed
risk: green
rationale: ''
mitigation: ''
- order: 5
text: >-
Chaos engineering approach, constant testing in production
(example: A/B testing + experimentation)
risk: green
rationale: ''
mitigation: ''
- order: 2
text: How is the application configured?
explanation: >-
How is the application configured? Is the configuration method
appropriate for a container? External servers are runtime
dependencies.
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: >-
Configuration files compiled during installation and configured
using a user interface
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Configuration files are stored externally (example: in a database)
and accessed using specific environment keys (examples: host name,
IP address)
risk: red
rationale: ''
mitigation: ''
- order: 3
text: Multiple configuration files in multiple file system locations
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: >-
Configuration files built into the application and enabled using
system properties at runtime
risk: yellow
rationale: ''
mitigation: ''
- order: 5
text: >-
Configuration retrieved from an external server (examples: Spring
Cloud Config Server, HashiCorp Consul)
risk: yellow
rationale: ''
mitigation: ''
- order: 6
text: >-
Configuration loaded from files in a single configurable location;
environment variables used
risk: green
rationale: ''
mitigation: ''
- order: 4
text: How is the application deployed?
explanation: >-
How the application is deployed and whether the deployment process is
suitable for a container platform
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 3
text: Simple automated deployment scripts
risk: yellow
rationale: ''
mitigation: ''
- order: 1
text: Manual deployment using a user interface
risk: red
rationale: ''
mitigation: ''
- order: 2
text: Manual deployment with some automation
risk: red
rationale: ''
mitigation: ''
- order: 4
text: >-
Automated deployment with manual intervention or complex promotion
through pipeline stages
risk: yellow
rationale: ''
mitigation: ''
- order: 5
text: >-
Automated deployment with a full CI/CD pipeline, minimal
intervention for promotion through pipeline stages
risk: green
rationale: ''
mitigation: ''
- order: 6
text: Fully automated (GitOps), blue-green, or canary deployment
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Where is the application deployed?
explanation: Where does the application run?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Bare metal server
risk: green
rationale: ''
mitigation: ''
- order: 2
text: 'Virtual machine (examples: red Hat Virtualization, VMware)'
risk: green
rationale: ''
mitigation: ''
- order: 3
text: 'Private cloud (example: red Hat OpenStack Platform)'
risk: green
rationale: ''
mitigation: ''
- order: 4
text: >-
Public cloud provider (examples: Amazon Web Services, Microsoft
Azure, Google Cloud Platform)
risk: green
rationale: ''
mitigation: ''
- order: 5
text: >-
Platform as a service (examples: Heroku, Force.com, Google App
Engine)
risk: yellow
rationale: ''
mitigation: ''
- order: 7
text: Other. Specify in the comments field
risk: yellow
rationale: ''
mitigation: ''
- order: 6
text: Hybrid cloud (public and private cloud providers)
risk: green
rationale: ''
mitigation: ''
- order: 6
text: How mature is the containerization process, if any?
explanation: If the team has used containers in the past, how was it done?
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Application runs in a container on a laptop or desktop
risk: red
rationale: ''
mitigation: ''
- order: 3
text: Some experience with containers but not yet fully defined
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: >-
Proficient with containers and container platforms (examples:
Swarm, Kubernetes)
risk: green
rationale: ''
mitigation: ''
- order: 5
text: Application containerization has not yet been attempted
risk: green
rationale: ''
mitigation: ''
- order: 3
text: How does the application acquire security keys or certificates?
explanation: >-
How does the application retrieve credentials, keys, or certificates?
External systems are runtime dependencies.
answers:
- order: 0
text: unknown
risk: unknown
rationale: ''
mitigation: ''
- order: 1
text: Hardware security modules or encryption devices
risk: red
rationale: ''
mitigation: ''
- order: 2
text: >-
Keys/certificates bound to IP addresses and generated at runtime
for each application instance
risk: red
rationale: ''
mitigation: ''
- order: 3
text: Keys/certificates compiled into the application
risk: yellow
rationale: ''
mitigation: ''
- order: 4
text: Loaded from a shared disk
risk: yellow
rationale: ''
mitigation: ''
- order: 5
text: >-
Retrieved from an external server (examples: HashiCorp Vault,
CyberArk Conjur)
risk: yellow
rationale: ''
mitigation: ''
- order: 6
text: Loaded from files
risk: green
rationale: ''
mitigation: ''
- order: 7
text: Not required
risk: green
rationale: ''
mitigation: ''
thresholds:
red: 5
yellow: 30
unknown: 5
riskMessages:
red: ''
yellow: ''
green: ''
unknown: ''
builtin: true7.2.2. The custom assessment questionnaire
You can use the Migration Toolkit for Applications (MTA) to import a custom assessment questionnaire by using a custom YAML syntax to define the questionnaire. The YAML syntax supports the following features:
- Conditional questions
-
The YAML syntax supports including or excluding questions based on tags existing on the application or archetype, for example:
-
If the application or archetype has the
Language/Javatag, theWhat is the main JAVA framework used in your application?question is included in the questionnaire:... questions: - order: 1 text: What is the main JAVA framework used in your application? explanation: Identify the primary JAVA framework used in your application. includeFor: - category: Language tag: Java ... -
If the application or archetype has the
Deployment/ServerlessandArchitecture/Monolithtag, theAre you currently using any form of container orchestration?question is excluded from the questionnaire:... questions: - order: 4 text: Are you currently using any form of container orchestration? explanation: Determine if the application utilizes container orchestration tools like Kubernetes, Docker Swarm, etc. excludeFor: - category: Deployment tag: Serverless - category: Architecture tag: Monolith ...
-
- Automated answers based on tags present on the assessed application or archetype
-
Automated answers are selected based on the tags existing on the application or archetype. For example, if an application or archetype has the
Runtime/Quarkustag, theQuarkusanswer is automatically selected, and if an application or archetype has theRuntime/Spring Boottag, theSpring Bootanswer is automatically selected:... text: What is the main technology in your application? explanation: Identify the main framework or technology used in your application. answers: - order: 1 text: Quarkus risk: green autoAnswerFor: - category: Runtime tag: Quarkus - order: 2 text: Spring Boot risk: green autoAnswerFor: - category: Runtime tag: Spring Boot ... - Automatic tagging of applications based on answers
-
During the assessment, tags are automatically applied to the application or archetype based on the answer if this answer is selected. Note that the tags are transitive. Therefore, the tags are removed if the assessment is discarded. Each tag is defined by the following elements:
-
category: Category of the target tag (
String). -
tag: Definition for the target tag as (
String).
For example, if the selected answer is
Quarkus, theRuntime/Quarkustag is applied to the assessed application or archetype. If the selected answer isSpring Boot, theRuntime/Spring Boottag is applied to the assessed application or archetype:... questions: - order: 1 text: What is the main technology in your application? explanation: Identify the main framework or technology used in your application. answers: - order: 1 text: Quarkus risk: green applyTags: - category: Runtime tag: Quarkus - order: 2 text: Spring Boot risk: green applyTags: - category: Runtime tag: Spring Boot ... -
The YAML template for the custom questionnaire
You can use the following YAML template to build your custom questionnaire. You can download this template by clicking Download YAML template on the Assessment questionnaires page.
The YAML template for the custom questionnaire
name: Uploadable Cloud Readiness Questionnaire Template
description: This questionnaire is an example template for assessing cloud readiness. It serves as a guide for users to create and customize their own questionnaire templates.
required: true
sections:
- order: 1
name: Application Technologies
questions:
- order: 1
text: What is the main technology in your application?
explanation: Identify the main framework or technology used in your application.
includeFor:
- category: Language
tag: Java
answers:
- order: 1
text: Quarkus
risk: green
rationale: Quarkus is a modern, container-friendly framework.
mitigation: No mitigation needed.
applyTags:
- category: Runtime
tag: Quarkus
autoAnswerFor:
- category: Runtime
tag: Quarkus
- order: 2
text: Spring Boot
risk: green
rationale: Spring Boot is versatile and widely used.
mitigation: Ensure container compatibility.
applyTags:
- category: Runtime
tag: Spring Boot
autoAnswerFor:
- category: Runtime
tag: Spring Boot
- order: 3
text: Legacy Monolithic Application
risk: red
rationale: Legacy monoliths are challenging for cloud adaptation.
mitigation: Consider refactoring into microservices.
- order: 2
text: Does your application use a microservices architecture?
explanation: Assess if the application is built using a microservices architecture.
answers:
- order: 1
text: Yes
risk: green
rationale: Microservices are well-suited for cloud environments.
mitigation: Continue monitoring service dependencies.
- order: 2
text: No
risk: yellow
rationale: Non-microservices architectures may face scalability issues.
mitigation: Assess the feasibility of transitioning to microservices.
- order: 3
text: Unknown
risk: unknown
rationale: Lack of clarity on architecture can lead to unplanned issues.
mitigation: Conduct an architectural review.
- order: 3
text: Is your application's data storage cloud-optimized?
explanation: Evaluate if the data storage solution is optimized for cloud usage.
includeFor:
- category: Language
tag: Java
answers:
- order: 1
text: Cloud-Native Storage Solution
risk: green
rationale: Cloud-native solutions offer scalability and resilience.
mitigation: Ensure regular backups and disaster recovery plans.
- order: 2
text: Traditional On-Premises Storage
risk: red
rationale: Traditional storage might not scale well in the cloud.
mitigation: Explore cloud-based storage solutions.
- order: 3
text: Hybrid Storage Approach
risk: yellow
rationale: Hybrid solutions may have integration complexities.
mitigation: Evaluate and optimize cloud integration points.
thresholds:
red: 1
yellow: 30
unknown: 15
riskMessages:
red: Requires deep changes in architecture or lifecycle
yellow: Cloud friendly but needs minor changes
green: Cloud Native
unknown: More information neededThe custom questionnaire fields
Every custom questionnaire field marked as required is mandatory and must be completed. Otherwise, the YAML syntax will not validate on upload. Each subsection of the field defines a new structure or object in YAML, for example:
...
name: Testing
thresholds:
red: 30
yellow: 45
unknown: 5
...| Questionnaire field | Description |
|---|---|
|
The name of the questionnaire. This field must be unique for the entire MTA instance. |
|
A short description of the questionnaire. |
|
The definition of a threshold for each risk category of the application or archetype that is considered to be affected by that risk level. The threshold values can be the following:
The higher risk level always takes precedence. For example, if the |
|
Messages to be displayed in reports for each risk category. The risk_messages map is defined by the following fields:
|
|
A list of sections that the questionnaire must include.
|
7.3. Managing assessment questionnaires
By using the MTA user interface, you can perform the following actions on assessment questionnaires:
-
Display the questionnaire. You can also diplay the answer choices and their associated risk weight.
-
Export the questionnaire to the desired location on your system.
-
Import the questionnaire from your system.
WarningThe name of the imported questionnaire must be unique. If the name, which is defined in the YAML syntax ( name:<name of questionnaire>), is duplicated, the import will fail with the following error message:UNIQUE constraint failed: Questionnaire.Name. -
Delete an assessment questionnaire.
WarningWhen you delete the questionnaire, its answers for all applications that use it in all archetypes are also deleted. ImportantYou cannot delete the Legacy Pathfinder default questionnaire.
-
Depending on your scenario, perform one of the following actions:
-
Display the quest the assessment questionnaire:
-
In the Administration view, select Assessment questionnaires.
-
Click the Options menu (
). -
Select View for the questionnaire you want to display.
-
Optional: Click the arrow to the left from the question to display the answer choices and their risk weight.
-
-
Export the assessment questionnaire:
-
In the Administration view, select Assessment questionnaires.
-
Select the desired questionnaire.
-
Click the Options menu (
). -
Select Export.
-
Select the location of the download.
-
Click Save.
-
-
Import the assessment questionnaire:
-
In the Administration view, select Assessment questionnaires.
-
Click Import questionnaire.
-
Click Upload.
-
Navigate to the location of your questionnaire.
-
Click Open.
-
Import the desired questionnaire by clicking Import.
-
-
Delete the assessment questionnaire:
-
In the Administration view, select Assessment questionnaires.
-
Select the questionnaire you want to delete.
-
Click the Options menu (
). -
Select Delete.
-
Confirm deleting by entering on the Name of the questionnaire.
-
-
7.4. Assessing an application
You can estimate the risks and costs involved in preparing applications for containerization by performing application assessment. You can assess an application and display the currently saved assessments by using the Assessment module.
The Migration Toolkit for Applications (MTA) assesses applications according to a set of questions relevant to the application, such as dependencies.
To assess the application, you can use the default Legacy Pathfinder MTA questionnaire or import your custom questionnaires.
|
Important
|
You can assess only one application at a time. |
-
You are logged in to an MTA server.
-
In the MTA user interface, select the Migration view.
-
Click Application inventory in the left menu bar. A list of the available applications appears in the main pane.
-
Select the application you want to assess.
-
Click the Options menu (
) at the right end of the row and select Assess from the drop-down menu. -
From the list of available questionnaires, click Take for the desired questionnaire.
-
Select Stakeholders and Stakeholder groups from the lists to track who contributed to the assessment for future reference.
NoteYou can also add Stakeholder Groups or Stakeholders in the Controls pane of the Migration view. For more information, see Seeding an instance. -
Click Next.
-
Answer each Application assessment question and click Next.
-
Click Save to review the assessment and proceed with the steps in Reviewing an application.
7.5. Reviewing an application
You can use the Migration Toolkit for Applications (MTA) user interface to determine the migration strategy and work priority for each application.
|
Important
|
You can review only one application at a time. |
-
In the Migration view, click Application inventory.
-
Select the application you want to review.
-
Review the application by performing either of the following actions:
-
Click Save and Review while assessing the application. For more information, see Assessing an application.
-
Click the Options menu (
) at the right end of the row and select Review from the drop-down list. The application Review parameters appear in the main pane.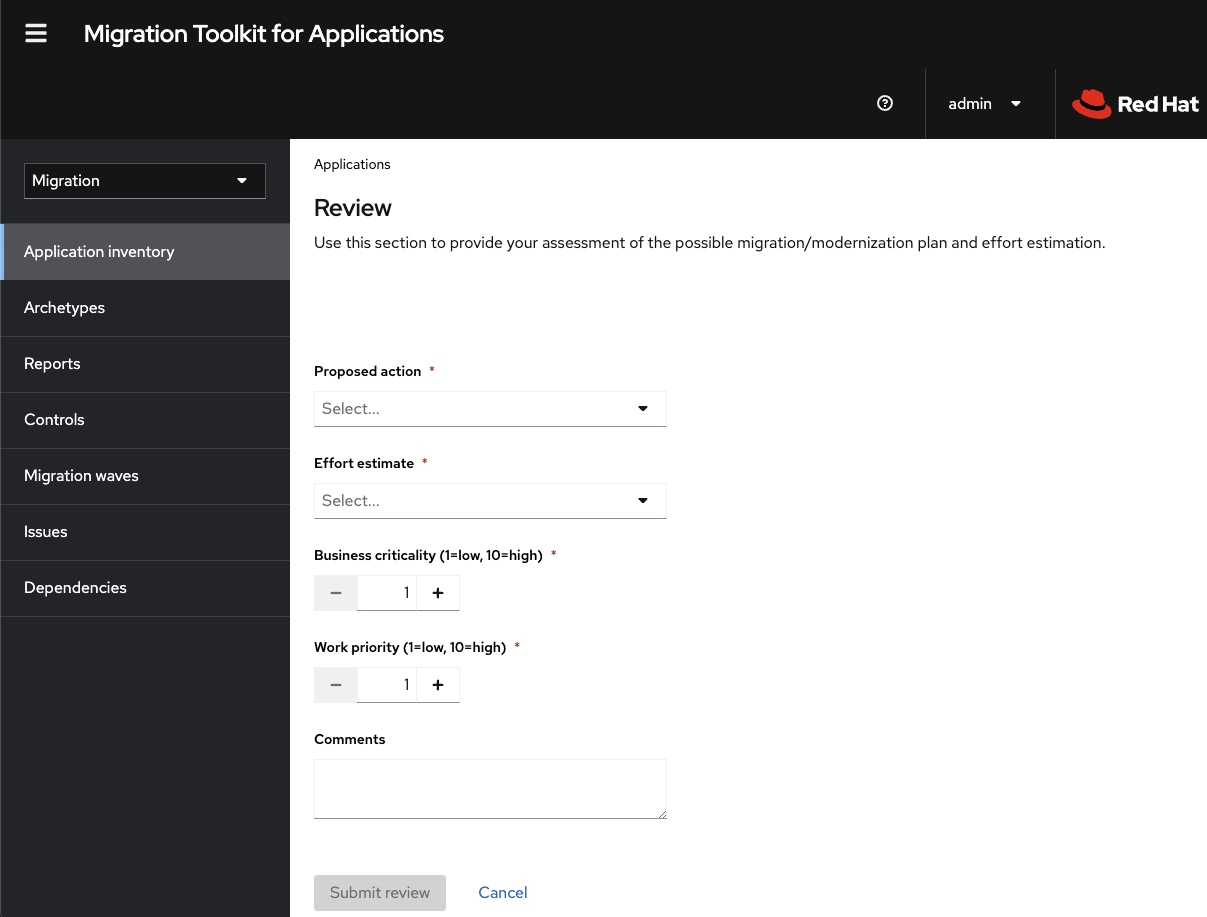
-
-
Click Proposed action and select the action.
-
Click Effort estimate and set the level of effort required to perform the assessment with the selected questionnaire.
-
In the Business criticality field, enter how critical the application is to the business.
-
In the Work priority field, enter the application’s priority.
-
Optional: Enter the assessment questionnaire comments in the Comments field.
-
Click Submit review.
The fields from Review are now populated on the Application details page.
7.6. Reviewing an assessment report
An MTA assessment report displays an aggregated assessment of the data obtained from multiple questionnaires for multiple applications.
-
In the Migration view, click Reports. The aggregated assessment report for all applications is displayed.
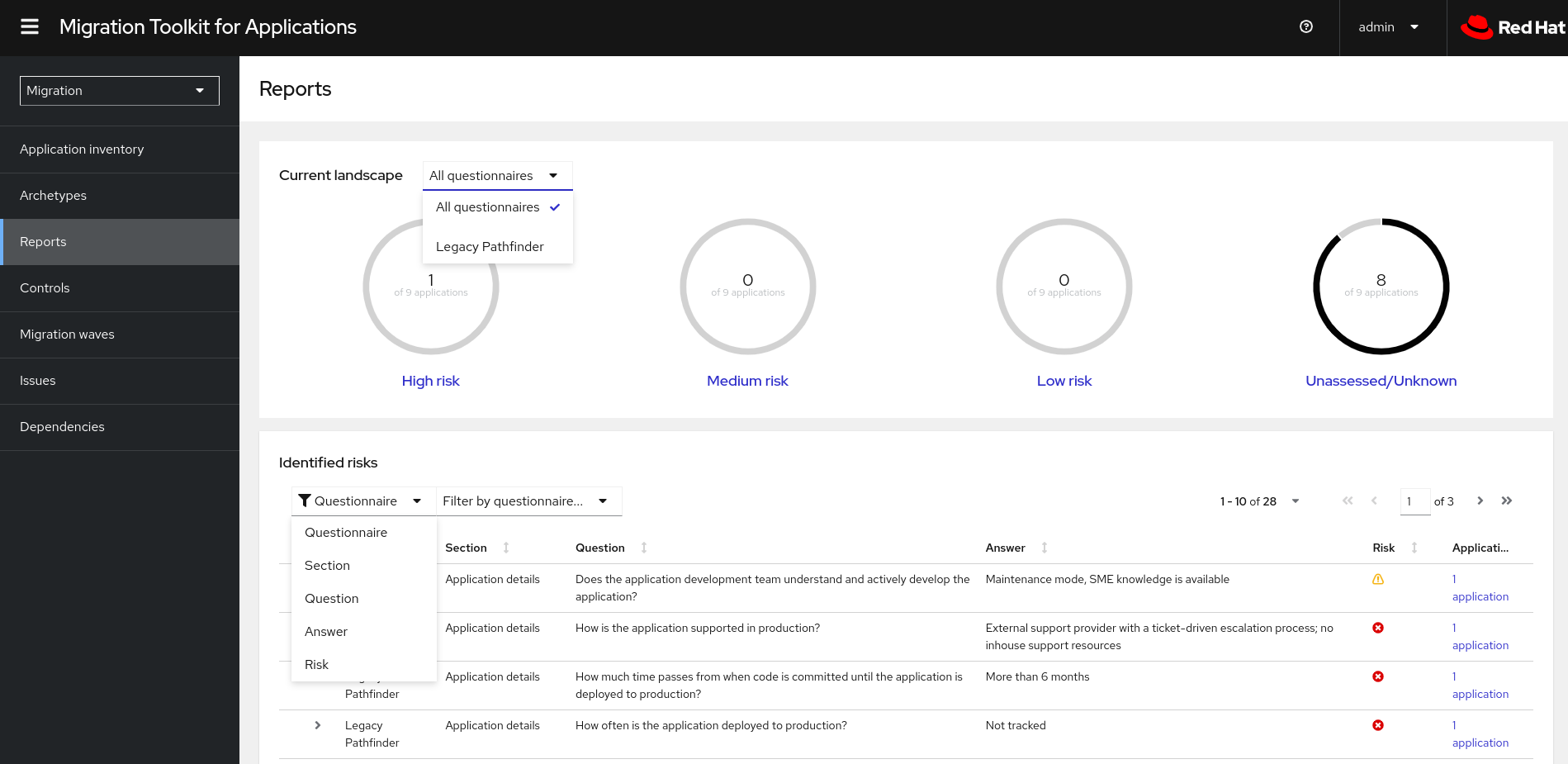
-
Depending on your scenario, perform one of the following actions:
-
Display a report on the data from a particular questionnaire:
-
Select the required questionnaire from a drop-down list of all questionnaires in the Current landscape pane of the report. By default, all questionnaires are selected.
-
In the Identified risks pane of the report, sort the displayed list by application name, level of risk, questionnaire, questionnaire section, question, and answer.
-
-
Display a report for a specific application:
-
Click the link in the Applications column in the Identified risks pane of the report. The Application inventory page opens. The applications included in the link are displayed as a list.
-
Click the required application. The Assessment side pane opens.
-
To see the assessed risk level for the application, open the Details tab.
-
To see the details of the assessment, open the Reviews tab.
-
-
-
7.7. Tagging an application
You can attach various tags to the application that you are analyzing. You can use tags to classify applications and instantly identify application information, for example, an application type, data center location, and technologies used within the application. You can also use tagging to associate archetypes to applications for automatic assessment. For more information about archetypes, see Working with archetypes.
Tagging can be done automatically during the analysis manually at any time.
|
Note
|
Not all tags can be assigned automatically. For example, an analysis can only tag the application based on its technologies. If you want to tag the application also with the location of the data center where it is deployed, you need to tag the application manually. |
7.7.1. Creating application tags
You can create custom tags for applications that MTA assesses or analyzes.
-
In the Migration view, click Controls.
-
Click the Tags tab.
-
Click Create tag.
-
In the Name field in the opened dialogue, enter a unique name for the tag.
-
Click the Tag category field and select the category tag to associate with the tag.
-
Click Create.
-
Optional: Edit the created tag or tag category:
-
Edit the tag:
-
In the list of tag categories under the Tags tab, open the list of tags in the desired category.
-
Select Edit from the drop-down menu and edit the tag name in the Name field.
-
Click the Tag category field and select the category tag to associate with the tag.
-
Click Save.
-
-
Edit the tag category:
-
Under the Tags tab, select a defined tag category and click Edit.
-
Edit the tag category’s name in the Name field.
-
Edit the category’s Rank value.
-
Click the Color field and select a color for the tag category.
-
Click Save.
-
-
7.7.2. Manually tagging an application
You can tag an application manually, both before or after you run an application analysis.
-
In the Migration view, click Application inventory.
-
In the row of the required application, click Edit (
). The Update application window opens. -
Select the desired tags from the Select a tag(s) drop-down list.
-
Click Save.
7.7.3. Automatic tagging
MTA can automatically add tags to the application based on the application analysis. Automatic tagging is especially useful when dealing with large portfolios of applications.
Automatic tagging of applications is enabled by default. You can disable automatic tagging by deselecting the Enable automated tagging checkbox in the Advanced section of the Analysis configuration wizard.
|
Note
|
To tag an application automatically, make sure that the Enable automated tagging checkbox is selected before you run an application analysis. |
7.7.4. Displaying application tags
You can display the tags attached to a particular application.
|
Note
|
You can display the tags that were attached automatically only after you have run an application analysis. |
-
In the Migration view, click Application inventory.
-
Click the name of the required application. A side pane opens.
-
Click the Tags tab. The tags attached to the application are displayed.
7.8. Working with archetypes
An archetype is a group of applications with common characteristics. You can use archetypes to assess multiple applications at once. By using archetypes, the Migration Toolkit for Applications (MTA) can apply questionnaires populated with questions that apply to common application characteristics.
Application archetypes are defined by criteria tags and the application taxonomy. Each archetype defines how the assessment module assesses the application according to the characteristics defined in that archetype. If the tags of an application match the criteria tags of an archetype, the application is associated with the archetype.
Creation of an archetype is defined by a series of tags, stakeholders, and stakeholder groups. The tags include the following types:
-
Criteria tags are tags that the archetype requires to include an application as a member.
NoteIf the archetype criteria tags match an application only partially, this application cannot be a member of the archetype. For example, if the application a only has tag a, but the archetype a criteria tags include tags a AND b, the application a will not be a member of the archetype a. -
Archetype tags are tags that are applied to the archetype entity.
|
Note
|
All applications associated with the archetype inherit the assessment and review from the archetype groups to which these applications belong. This is the default setting. You can override inheritance for the application by completing an individual assessment and review. |
7.8.1. Creating an archetype
When you create an archetype, an application in the inventory is automatically associated to that archetype if this application has the tags that match the tags of the archetype.
-
Open the MTA web console.
-
In the left menu, click Archetypes.
-
Click Create new archetype.
-
In the form that opens, enter the following information for the new archetype:
-
Name: A name of the new archetype (mandatory).
-
Description: A description of the new archetype (optional).
-
Criteria Tags: Tags that associate the assessed applications with the archetype (mandatory). If criteria tags are updated, the process to calculate the applications, which the archetype is associated with, is triggered again.
-
Archetype Tags: Tags that the archetype assesses in the application (mandatory).
-
Stakeholder(s): Specific stakeholders involved in the application development and migration (optional).
-
Stakeholders Group(s): Groups of stakeholders involved in the application development and migration (optional).
-
-
Click Create.
7.8.2. Archetype assessment
An archetype is considered assessed when all required questionnaires have been answered.
An archetype is considered reviewed when it has been reviewed once even if multiple questionnaires have been marked as required.
If an application is associated with archetypes, this application is considered assessed when all associated archetypes have been assessed.
7.8.3. Deleting an archetype
Deleting an archetype deletes any associated assessment. All associated applications move to the Unassessed state.
7.9. Analyzing an application
You can use the Migration Toolkit for Applications (MTA) user interface to configure and run an application analysis. The analysis determines which specific lines in the application must be modified before the application can be migrated or modernized.
7.9.1. Configuring and running an application analysis
You can analyze more than one application at a time against more than one transformation target in the same analysis.
-
In the Migration view, click Application inventory.
-
Select an application that you want to analyze.
-
Review the credentials assigned to the application.
-
Click Analyze.
-
Select the Analysis mode from the list:
-
Binary
-
Source code
-
Source code and dependencies
-
Upload a local binary. This option only appears if you are analyzing a single application. If you chose this option, you are prompted to Upload a local binary. Either drag a file into the area provided or click Upload and select the file to upload.
-
-
Click Next.
-
Select one or more target options for the analysis:
-
Application server migration to either of the following platforms:
-
JBoss EAP 7
-
JBoss EAP 8
-
-
Containerization
-
Quarkus
-
OracleJDK to OpenJDK
-
OpenJDK. Use this option to upgrade to either of the following JDK versions:
-
OpenJDK 11
-
OpenJDK 17
-
OpenJDK 21
-
-
Linux. Use this option to ensure that there are no Microsoft Windows paths hard-coded into your applications.
-
Jakarta EE 9. Use this option to migrate from Java EE 8.
-
Spring Boot on Red Hat Runtimes
-
Open Liberty
-
Camel. Use this option to migrate from Apache Camel 2 to Apache Camel 3 or from Apache Camel 3 to Apache Camel 4.
-
Azure App Service
-
-
Click Next.
-
Select one of the following Scope options to better focus the analysis:
-
Application and internal dependencies only.
-
Application and all dependencies, including known Open Source libraries.
-
Select the list of packages to be analyzed manually. If you choose this option, type the file name and click Add.
-
Exclude packages. If you choose this option, type the name of the package and click Add.
-
-
Click Next.
-
In Advanced, you can attach additional custom rules to the analysis by selecting the Manual or Repository mode:
-
In the Manual mode, click Add Rules. Drag the relevant files or select the files from their directory and click Add.
-
In the Repository mode, you can add rule files from a Git or Subversion repository.
ImportantAttaching custom rules is optional if you have already attached a migration target to the analysis. If you have not attached any migration target, you must attach rules.
-
-
Optional: Set any of the following options:
-
Target
-
Source(s)
-
Excluded rules tags. Rules with these tags are not processed. Add or delete as needed.
-
Enable automated tagging. Select the checkbox to automatically attach tags to the application. This checkbox is selected by default.
NoteAutomatically attached tags are displayed only after you run the analysis.
You can attach tags to the application manually instead of enabling automated tagging or in addition to it.
NoteAnalysis engines use standard rules for a comprehensive set of migration targets, but if the target is not included or is a customized framework, custom rules can be added. Only manually uploaded custom rule files are validated.
-
-
Click Next.
-
In Review, verify the analysis parameters.
-
Click Run.
The analysis status is
Scheduledas MTA downloads the image for the container to execute. When the image is downloaded, the status changes toIn-progress.NoteAnalysis takes minutes to hours to run depending on the size of the application and the capacity and resources of the cluster.
TipMTA relies on Kubernetes scheduling capabilities to determine how many analyzer instances are created based on cluster capacity. If several applications are selected for analysis, by default, only one analyzer can be provisioned at a time. With more cluster capacity, more analysis processes can be executed in parallel.
-
When analysis is complete, click the Report link to see the results of the analysis.
-
Optional: Display the details of the analysis:
-
Click the Options menu (
). -
Select Analysis details. You can choose either the YAML or JSON format.
-
7.9.2. Reviewing an analysis report
An MTA analysis report contains a number of sections, including a listing of the technologies used by the application, the dependencies of the application, and the lines of code that must be changed to successfully migrate or modernize the application.
For more information about the contents of an MTA analysis report, see Reviewing the reports.
-
In the Migration view, click Application inventory.
-
Expand the application with a completed analysis.
-
Click Reports.
-
Click the dependencies or source links.
-
Click the tabs to review the report.
7.9.3. Downloading an analysis report
For your convenience, you can download analysis reports. Note that by default this option is disabled.
-
In Administration view, click General.
-
Toggle the Allow reports to be downloaded after running an analysis. switch.
-
Go to the Migration view and click Application inventory.
-
Open the page of the application for which you ran an analysis.
-
Click Reports.
-
Click either the HTML or YAML link:
-
By clicking the HTML link, you download the compressed
analysis-report-app-<application_name>.tarfile. Extracting this file creates a folder with the same name as the application. -
By clicking the YAML link, you download the uncompressed
analysis-report-app-<application_name>.yamlfile.
-
7.10. Creating custom migration targets
Architects or users with admin permissions can create and maintain custom rulesets associated with custom migration targets. Architects can upload custom rule files and assign them to various custom migration targets. The custom migration targets can then be selected in the analysis configuration wizard.
By using ready-made custom migration targets, you can avoid configuring custom rules for each analysis run. This simplifies analysis configuration and execution for non-admin users or third-party developers.
-
You are logged in as a user with
adminpermissions.
-
In the Administration view, click Custom migration targets.
-
Click Create new.
-
Enter the name and description of the target.
-
In the Image section, upload an image file for the target’s icon. The file can be in either the PNG or JPEG format, up to 1 MB. If you do not upload any file, a default icon is used.
-
In the Custom rules section, select either Upload manually or Retrieve from a repository:
-
If you selected Upload manually, upload or drag and drop the required rule files from your local drive.
-
If you selected Retrieve from a repository, complete the following steps:
-
Choose Git or Subversion.
-
Enter the Source repository, Branch, and Root path fields.
-
If the repository requires credentials, enter these credentials in the Associated credentials field.
-
-
-
Click Create.
The new migration target appears on the Custom migration targets page. It can now be used by non-admin users in the Migration view.
Revised on 2025-03-02 19:15:00 CST